SQLite Data Dictionary mit Markdown erstellen: Dokumentation direkt neben der Datenbank
Mit SQLite Hub ein Data Dictionary in Markdown erstellen, Tabellen und Spalten dokumentieren und gespeicherte SQL-Abfragen direkt einbinden
Dieser Artikel hat eine Lesedauer von 11 minutes Minuten.
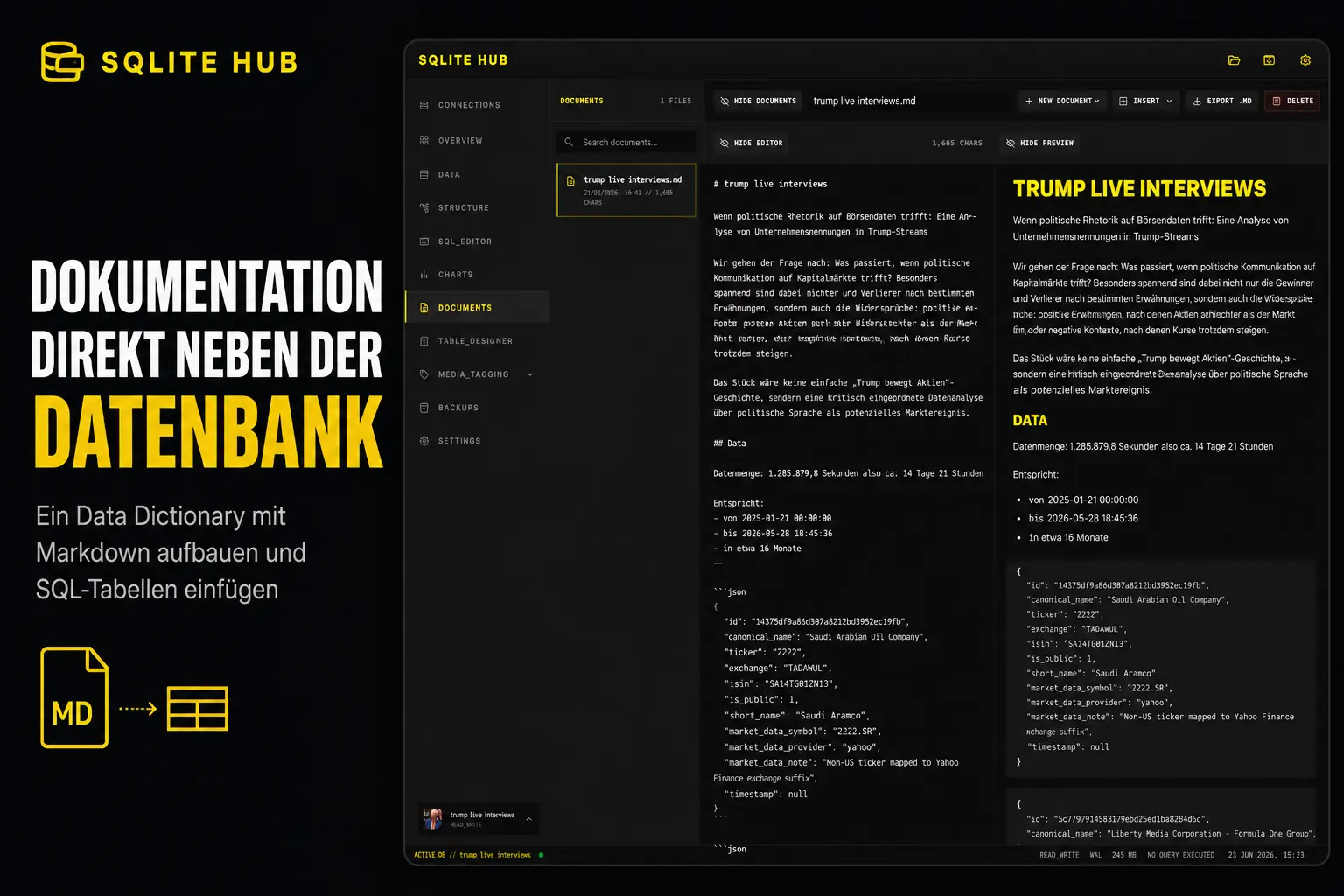
Ein SQLite-Schema zeigt Strukturen, aber selten deren fachliche Bedeutung. Mit SQLite Hub entsteht ein Data Dictionary aus Markdown, SQL-Abfragen und datenbankbezogenen Notizen.
SQLite Data Dictionary erstellen: Das Wichtigste in Kürze
Ein SQLite Data Dictionary dokumentiert, welche Tabellen und Spalten eine Datenbank enthält und welche fachliche Bedeutung hinter den gespeicherten Werten steckt.
Das technische SQLite-Schema liefert dafür bereits wichtige Grundlagen. Es zeigt unter anderem Datentypen, Primärschlüssel, Fremdschlüssel, Indizes und Constraints. Es erklärt jedoch nicht automatisch, warum eine Tabelle existiert, aus welcher Quelle ein Wert stammt oder welche Bedeutung ein Status besitzt.
Für diese zusätzliche Ebene habe ich in SQLite Hub einen datenbankbezogenen Dokumentenbereich integriert. Dort kann ich:
- Markdown-Dokumente für eine Datenbank anlegen
- Tabellen und Spalten beschreiben
- fachliche Regeln und erlaubte Werte festhalten
- Ergebnisse gespeicherter SQL-Abfragen einfügen
- Notizen aus gespeicherten Abfragen übernehmen
- offene Fragen als Aufgabenlisten verwalten
- Dokumente als
.md-Dateien exportieren - Dokumente über die SQLite-Hub-CLI abrufen
Die Dokumentation wird nicht in die eigentliche SQLite-Datei geschrieben. Sie bleibt getrennt gespeichert, ist aber innerhalb von SQLite Hub eindeutig der jeweiligen Datenbank zugeordnet.
Der Dokumentenbereich ist Teil des größeren lokalen Workflows, den ich im Überblick über SQLite Hub als SQLite Database Manager beschreibe.
Was ist ein Data Dictionary?
Ein Data Dictionary ist ein strukturierter Katalog der Daten einer Anwendung. Im Deutschen wird dafür teilweise auch der Begriff Datenwörterbuch verwendet.
Das Data Dictionary beschreibt nicht nur die technische Struktur einer Datenbank. Es ergänzt sie um fachlichen Kontext und beantwortet beispielsweise folgende Fragen:
- Welchen Zweck erfüllt eine Tabelle?
- Was bedeutet eine bestimmte Spalte?
- Welche Werte sind erlaubt?
- Welche Einheit besitzt eine Zahl?
- In welchem Format werden Zeitstempel gespeichert?
- Aus welcher Quelle stammen die Daten?
- Welche Beziehung besteht zwischen zwei Tabellen?
- Welche Felder können
NULLenthalten? - Welche Werte gelten als veraltet oder gelöscht?
- Welche Annahmen liegen einer Auswertung zugrunde?
Ein gutes Data Dictionary hilft damit nicht nur beim Lesen einer Datenbank. Es reduziert auch das Risiko, dass Abfragen, Exporte oder Änderungen auf falschen Annahmen beruhen.
Gerade bei einer unbekannten oder länger nicht verwendeten SQLite-Datenbank kann diese zusätzliche Dokumentation viel Zeit sparen.
Warum das SQLite-Schema allein nicht ausreicht
SQLite speichert die technische Struktur einer Datenbank im Schema. Mit Abfragen und PRAGMA-Anweisungen lassen sich Tabellen, Spalten, Schlüssel, Indizes und Beziehungen untersuchen.
Eine Spalte kann beispielsweise so definiert sein:
status TEXT NOT NULL
Diese Definition verrät, dass status einen Textwert enthalten muss. Sie erklärt aber nicht, welche Werte erlaubt sind oder wann ein Status geändert wird.
Mögliche Werte könnten sein:
pendingpaidshippedcancelled
Auch deren Bedeutung bleibt offen. Bedeutet cancelled, dass eine Bestellung manuell storniert wurde? Wird eine fehlgeschlagene Zahlung ebenfalls als Stornierung behandelt? Können stornierte Datensätze später reaktiviert werden?
Solche Regeln lassen sich teilweise über Constraints im Schema absichern. Die fachliche Erklärung fehlt jedoch weiterhin.
Ähnlich sieht es bei Spalten wie diesen aus:
created_at
source_id
score
type
active
deleted_at
Die Namen wirken zunächst verständlich. In einem konkreten Projekt können sie aber sehr unterschiedliche Bedeutungen haben.
created_at könnte beispielsweise:
- einen Unix-Zeitstempel in Sekunden enthalten
- einen Unix-Zeitstempel in Millisekunden enthalten
- als ISO-8601-Text gespeichert sein
- den Importzeitpunkt statt des eigentlichen Erstellungszeitpunkts beschreiben
Ohne Dokumentation muss dieser Kontext aus Anwendungscode, Importskripten oder Beispieldaten rekonstruiert werden. Für technische Strukturen kann das Schema dagegen direkt weiterverwendet werden. SQLite Hub kann daraus beispielsweise TypeScript-, Kotlin-, Swift- und Rust-Typen generieren. Das Data Dictionary ergänzt diese technische Ableitung um den fachlichen Kontext.
Warum ich Markdown für das Data Dictionary verwende
Für die Dokumentenfunktion von SQLite Hub wollte ich kein proprietäres Dateiformat entwickeln. Markdown ist einfach lesbar, weit verbreitet und unabhängig von einem bestimmten Editor.
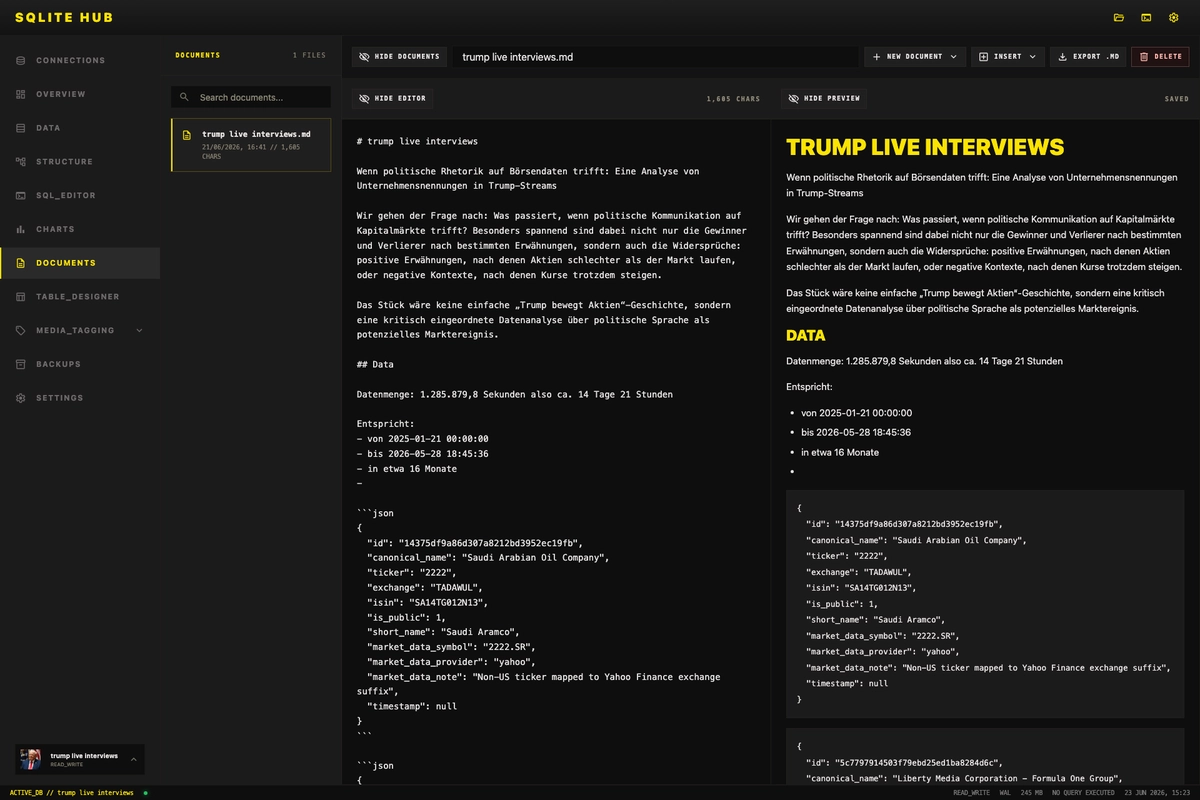
Ein Markdown-Dokument kann auch außerhalb von SQLite Hub geöffnet, durchsucht und bearbeitet werden. Es lässt sich außerdem in Git versionieren oder in andere Dokumentationssysteme übernehmen.
Für ein Data Dictionary bietet Markdown alle wichtigen Elemente:
- Überschriften für Tabellen und Themenbereiche
- Tabellen für Spaltenbeschreibungen
- Listen für Regeln und Wertebereiche
- Codeblöcke für SQL-Abfragen
- Links zu weiterführenden Informationen
- Checkboxen für offene Aufgaben
- Fließtext für fachliche Erklärungen
Gerade in der Softwareentwicklung ist diese Portabilität für mich wichtiger als ein besonders komplexes Dokumentationsformat.
Die Dokumentation soll nicht von SQLite Hub abhängig werden. Sie soll auch dann lesbar bleiben, wenn die Datei später in einem Texteditor, einem Git-Repository oder einem anderen Markdown-System geöffnet wird.
SQLite-Datenbanken direkt in SQLite Hub dokumentieren
SQLite Hub verwaltet Markdown-Dokumente datenbankbezogen. Für jede geöffnete Datenbank steht ein eigener Dokumentenbereich zur Verfügung.
Dadurch bleibt klar, welche Beschreibung zu welcher SQLite-Datei gehört. Das ist besonders hilfreich, wenn mehrere Datenbanken ähnliche Tabellen oder gleichnamige Spalten enthalten.
Im Dokumentenbereich kann ich:
- ein neues Dokument anlegen
- vorhandene Markdown-Dateien importieren
- Dokumente bearbeiten
- zwischen Quelltext und Vorschau wechseln
- Tabellen und Codeblöcke darstellen
- Aufgabenlisten verwenden
- gespeicherte Abfragen einbinden
- Dokumente wieder als Markdown exportieren
Mit “Dokumentation direkt neben der Datenbank” meine ich deshalb die inhaltliche Zuordnung innerhalb des Arbeitsbereichs.
SQLite Hub verändert dafür nicht das Format der Datenbank. Die eigentliche .db-, .sqlite- oder .sqlite3-Datei bleibt eine gewöhnliche SQLite-Datei.
SQLite Data Dictionary als Markdown-Datei aufbauen
Bei einer kleinen Datenbank reicht häufig ein einzelnes Dokument. Größere Projekte können mehrere Dokumente nach Tabellenbereichen, Datenquellen oder Anwendungsmodulen verwenden.
Ein einfaches Data Dictionary kann mit einer allgemeinen Übersicht beginnen:
# Data Dictionary: shop.db
## Zweck der Datenbank
Die Datenbank enthält Kundenkonten, Bestellungen und importierte
Produktinformationen eines lokalen Shop-Prototyps.
## Technische Grundlagen
- Zeitstempel werden als Unix-Zeit in Sekunden gespeichert
- Geldbeträge werden als Integer in Cent gespeichert
- Fremdschlüssel sind in der Anwendung aktiviert
- Gelöschte Bestellungen bleiben für Auswertungen erhalten
- Produktdaten stammen aus einem täglichen CSV-Import
## Verantwortlichkeit
- Anwendung: Local Shop
- Datenquelle: SQLite
- Verantwortlich: Backend-Team
- Letzte Prüfung: 2026-06-25
Dieser Einstieg dokumentiert Regeln, die für mehrere Tabellen gelten. Dadurch müssen sie nicht in jeder Tabellenbeschreibung wiederholt werden.
Sinnvolle allgemeine Angaben sind:
- Zweck der Datenbank
- Name der zugehörigen Anwendung
- Herkunft der Daten
- verwendete Zeitformate
- verwendete Maßeinheiten
- Umgang mit gelöschten Datensätzen
- Namenskonventionen
- verantwortliche Rolle
- Datum der letzten Prüfung
Tabellen und Spalten dokumentieren
Nach der allgemeinen Übersicht beschreibe ich die wichtigsten Tabellen einzeln.
Eine Markdown-Tabelle eignet sich dafür besonders gut:
## Tabelle: orders
Speichert Bestellungen, ihren aktuellen Bearbeitungsstand und den
zugehörigen Kunden.
| Spalte | SQLite-Typ | Bedeutung | Beispiel |
| ----------- | ---------- | -------------------------------- | ---------- |
| id | INTEGER | Interne Bestellnummer | 1842 |
| customer_id | INTEGER | Verweis auf customers.id | 91 |
| status | TEXT | Aktueller Bearbeitungsstand | shipped |
| total_cents | INTEGER | Gesamtbetrag in Cent | 12990 |
| created_at | INTEGER | Unix-Zeit in Sekunden | 1782374400 |
| deleted_at | INTEGER | Zeitpunkt der logischen Löschung | NULL |
Neben dem Datentyp sollte die Beschreibung vor allem jene Informationen enthalten, die sich nicht zuverlässig aus dem Schema ableiten lassen.
Dazu gehören beispielsweise:
- fachliche Bedeutung
- Einheit
- Wertebereich
- Herkunft
- Format
- Beispielwert
- Umgang mit
NULL - Abhängigkeiten zu anderen Feldern
- bekannte Sonderfälle
Für die Spalte status kann anschließend ein eigener Abschnitt folgen:
### Erlaubte Statuswerte
- pending: Bestellung wurde angelegt
- paid: Zahlung wurde bestätigt
- shipped: Bestellung wurde versendet
- cancelled: Bestellung wurde storniert
### Fachliche Regeln
- Eine versendete Bestellung bleibt im Status shipped
- Stornierte Bestellungen werden nicht physisch gelöscht
- Eine Bestellung darf erst nach bestätigter Zahlung versendet werden
Damit ergänzt das Data Dictionary die technische Definition um Regeln aus der Anwendung.
Beziehungen zwischen Tabellen erklären
Fremdschlüssel zeigen, dass zwei Tabellen technisch miteinander verbunden sind. Sie erklären jedoch nicht immer den fachlichen Hintergrund der Beziehung.
Ein Abschnitt für Beziehungen kann deshalb so aussehen:
## Beziehungen
### orders.customer_id zu customers.id
Jede Bestellung gehört zu einem Kundenkonto.
Ein Kundenkonto kann mehrere Bestellungen besitzen. Wird ein Konto
deaktiviert, bleiben die zugehörigen Bestellungen erhalten.
### order_items.order_id zu orders.id
Jede Position gehört genau zu einer Bestellung.
Positionen werden gemeinsam mit der Bestellung verarbeitet und dürfen
nicht unabhängig verschoben werden.
Solche Hinweise sind besonders relevant, wenn Löschvorgänge, Importe oder Migrationen geplant werden.
Das Schema kann zeigen, ob ON DELETE CASCADE verwendet wird. Das Data Dictionary erklärt dagegen, ob dieses Verhalten fachlich gewollt ist.
Erlaubte Werte und Formate festhalten
Viele SQLite-Datenbanken verwenden TEXT- oder INTEGER-Spalten für Werte, die in der Anwendung eine genauere Bedeutung besitzen.
Typische Beispiele sind:
- Statuswerte
- Währungen
- Länderkennungen
- Zeitstempel
- boolesche Werte
- Kategorien
- Bewertungswerte
- externe Identifikatoren
Ein entsprechender Abschnitt könnte so aussehen:
## Formate und Konventionen
### Zeitstempel
Alle Zeitstempel werden als Unix-Zeit in Sekunden gespeichert.
Die Anwendung interpretiert sie als UTC.
### Geldbeträge
Geldbeträge werden als Integer in Cent gespeichert.
12990 entspricht daher 129,90 Euro.
### Boolesche Werte
- 0: false
- 1: true
- NULL: Status wurde noch nicht bestimmt
Gerade bei SQLite ist diese Dokumentation hilfreich, weil die flexible Typisierung der Datenbank verschiedene Speicherformen zulässt.
Gespeicherte SQL-Abfragen als Dokumentationsquelle
Eine rein statische Beschreibung zeigt nicht immer, welche Werte tatsächlich in einer Datenbank vorkommen.
Deshalb kann ich in SQLite Hub Ergebnisse gespeicherter SQL-Abfragen als Markdown-Tabelle in ein Dokument einfügen.
Eine Abfrage für die vorhandenen Bestellstatus könnte so aussehen:
SELECT
status,
COUNT(*) AS order_count
FROM orders
GROUP BY status
ORDER BY order_count DESC;
Speichere ich diese Abfrage im SQL-Editor, kann ich ihr einen Namen und eine erklärende Notiz geben. Wie sich solche Abfragen entwickeln, prüfen, speichern und wiederverwenden lassen, erkläre ich ausführlicher im Beitrag über den SQLite SQL-Editor von SQLite Hub.
Das Ergebnis lässt sich anschließend als Markdown-Tabelle in das Data Dictionary übernehmen:
| status | order_count |
| --------- | ----------: |
| shipped | 1284 |
| paid | 116 |
| pending | 42 |
| cancelled | 19 |
Damit verbindet das Dokument drei Ebenen:
- die technische Struktur der Datenbank
- die fachliche Erklärung der Werte
- einen konkreten Ausschnitt aus den vorhandenen Daten
Das ist beispielsweise bei Datenmigrationen, Importkontrollen oder Qualitätsprüfungen hilfreich.
Abfrageergebnisse bleiben Momentaufnahmen
Eine eingefügte Markdown-Tabelle ist eine Momentaufnahme. Sie aktualisiert sich nicht automatisch, wenn sich die zugrunde liegenden Daten ändern.
Das sollte im Dokument erkennbar sein:
## Verteilung der Bestellstatus
Abfrage ausgeführt am 2026-06-25.
| status | order_count |
| --------- | ----------: |
| shipped | 1284 |
| paid | 116 |
| pending | 42 |
| cancelled | 19 |
Für reproduzierbare Auswertungen sollte die zugehörige SQL-Abfrage zusätzlich in SQLite Hub gespeichert bleiben.
So kann ich die aktuelle Verteilung später erneut berechnen, ohne die Abfrage aus dem Markdown-Dokument kopieren zu müssen.
Notizen aus gespeicherten Abfragen übernehmen
Gespeicherte Abfragen können in SQLite Hub eigene Notizen enthalten. Diese Notizen lassen sich ebenfalls in ein Dokument einfügen.
Das bietet sich an, wenn eine Abfrage bestimmte Annahmen oder Filter verwendet:
## Aktive Kunden
Die Auswertung berücksichtigt nur Kunden, die innerhalb der letzten
180 Tage mindestens eine bezahlte Bestellung aufgegeben haben.
Stornierte Bestellungen werden nicht als Aktivität gewertet.
Testkonten werden über die Spalte is_test ausgeschlossen.
Die SQL-Abfrage bleibt im Abfrageverlauf gespeichert. Ihre fachliche Einordnung wird zusätzlich im Data Dictionary sichtbar.
Dadurch liegen SQL und Erklärung nicht mehr an vollständig getrennten Stellen.
Offene Datenfragen als Markdown-Aufgaben verwalten
Beim Aufbau eines Data Dictionary entstehen häufig neue Fragen.
Beispiele sind:
- Warum enthält eine Spalte unerwartete
NULL-Werte? - Wird ein Feld noch von der Anwendung verwendet?
- Aus welcher Quelle stammt eine externe ID?
- Welche Einheit verwendet eine numerische Spalte?
- Warum existieren Werte außerhalb des erwarteten Bereichs?
Solche Punkte lassen sich als Markdown-Aufgaben festhalten:
## Offene Fragen
- [x] Bedeutung von status dokumentieren
- [ ] Herkunft der Spalte source_id prüfen
- [ ] Alte NULL-Werte in created_at untersuchen
- [ ] Verantwortlichkeit für den Produktimport klären
- [ ] Prüfen, ob legacy_code noch verwendet wird
Damit ersetzt SQLite Hub kein vollständiges Ticketsystem. Kleine Aufgaben und ungeklärte Datenfragen bleiben aber direkt mit der untersuchten Datenbank verbunden.
SQLite-Dokumentation über die CLI abrufen
Die Markdown-Dokumente sind nicht nur über die grafische Oberfläche erreichbar. SQLite Hub besitzt eine integrierte CLI für datenbankbezogene Workflows.
Alle Dokumente einer Datenbank lassen sich mit folgendem Befehl auflisten:
sqlite-hub --database:Shop --documents
Der Inhalt eines bestimmten Dokuments kann direkt im Terminal ausgegeben werden:
sqlite-hub --database:Shop --documents:"Data Dictionary"
Soll das Dokument als .md-Datei in das aktuelle Verzeichnis exportiert werden, kommt --export hinzu:
sqlite-hub --database:Shop --documents:"Data Dictionary" --export
Dokumente können anhand ihrer ID, ihres Dateinamens, ihres Titels oder eines teilweise übereinstimmenden Namens gefunden werden. Weitere Möglichkeiten für Shell-Skripte, gespeicherte Queries und automatisierte Exporte zeigt der Guide SQLite CLI automatisieren.
Was gehört in ein Data Dictionary?
Ein Data Dictionary sollte sich auf Informationen konzentrieren, die beim Verstehen und Verwenden der Daten helfen.
Sinnvoll sind:
- Zweck der Datenbank
- Beschreibungen von Tabellen
- Beschreibungen von Spalten
- Datentypen und Formate
- erlaubte Werte
- Einheiten
- Beziehungen zwischen Tabellen
- Datenquellen
- Importregeln
- Regeln für gelöschte Datensätze
- bekannte Einschränkungen
- Hinweise zur Datenqualität
- Annahmen gespeicherter Abfragen
- Datum der letzten Prüfung
Nicht jede Tabelle benötigt dieselbe Detailtiefe. Technische Hilfstabellen können häufig kürzer beschrieben werden als zentrale Geschäftsobjekte.
Wichtiger als Vollständigkeit ist, dass die Dokumentation jene Fragen beantwortet, die sich aus Schema und Beispieldaten nicht eindeutig klären lassen.
Was nicht in die Datenbankdokumentation gehört
Ein Data Dictionary sollte kein allgemeines Projekt-Wiki ersetzen.
Weniger geeignet sind:
- vollständige Installationsanleitungen
- allgemeine Projektplanung
- Zugangsdaten
- API-Schlüssel
- Passwörter
- umfangreiche Architekturentscheidungen ohne Datenbankbezug
- personenbezogene Beispieldaten
- Informationen, die bereits zuverlässig an anderer Stelle gepflegt werden
Besondere Vorsicht ist bei eingefügten Abfrageergebnissen notwendig. Eine Markdown-Tabelle kann echte Datensätze enthalten.
Vor einem Export sollte deshalb geprüft werden, ob das Dokument sensible oder personenbezogene Inhalte enthält.
Ein Data Dictionary muss gepflegt werden
Markdown verhindert nicht, dass Dokumentation veraltet.
Wird eine Spalte umbenannt, ein Status ergänzt oder eine Importregel geändert, passt sich der beschreibende Text nicht automatisch an.
Ich ergänze deshalb einen kurzen Dokumentationsstatus:
## Dokumentationsstatus
- Verantwortlich: Backend-Team
- Letzte Prüfung: 2026-06-25
- Nächste Prüfung: nach der geplanten Importmigration
Bei größeren Schemaänderungen sollte das Data Dictionary Teil der Prüfung sein.
SQLite Hub zeigt das tatsächliche Schema weiterhin im Structure-Bereich an. Das Data Dictionary ergänzt diesen Zustand um Kontext, ersetzt ihn aber nicht als technische Quelle.
Mein praktischer Workflow für neue SQLite-Datenbanken
Bei einer neuen oder unbekannten Datenbank gehe ich meist schrittweise vor:
- Ich öffne die Datei in SQLite Hub.
- Ich prüfe Tabellen, Spalten, Schlüssel und Beziehungen im Structure-Bereich.
- Ich identifiziere Tabellen und Felder, deren Bedeutung nicht eindeutig ist.
- Ich lege ein Markdown-Dokument für das Data Dictionary an.
- Ich dokumentiere zuerst allgemeine Formate und Konventionen.
- Danach beschreibe ich die wichtigsten Tabellen und Spalten.
- Wiederverwendbare Analysen speichere ich im SQL-Editor.
- Relevante Ergebnisse übernehme ich als Markdown-Tabellen.
- Offene Fragen halte ich als Aufgabenliste fest.
- Nach Schemaänderungen prüfe ich die betroffenen Abschnitte erneut.
Das Ergebnis muss nicht sofort jede Tabelle vollständig beschreiben.
Bereits wenige präzise Definitionen können verhindern, dass spätere Änderungen oder Auswertungen auf falschen Annahmen beruhen.
SQLite Hub installieren
SQLite Hub ist ein lokaler und quelloffener Arbeitsbereich für SQLite. Die Datenbank bleibt dabei eine normale Datei auf dem eigenen System.
Unter macOS und Linux lässt sich SQLite Hub über Homebrew installieren:
brew tap oliverjessner/tap
brew install sqlite-hub
Alternativ steht die globale Installation über npm zur Verfügung:
npm install -g sqlite-hub
Nach dem Öffnen einer SQLite-Datei steht der Dokumentenbereich gemeinsam mit SQL-Editor, Datenansicht, Strukturansicht, Backups und Exportfunktionen zur Verfügung.
Dokumentation bleibt dort, wo mit den Daten gearbeitet wird
Mit den Markdown-Dokumenten wollte ich SQLite Hub nicht in ein umfassendes Wissensmanagement-System verwandeln.
Mein Ziel war konkreter: Fachlicher Kontext soll dort verfügbar sein, wo Tabellen untersucht, SQL-Abfragen geschrieben und Daten verändert werden.
Ein SQLite Data Dictionary aus Markdown erfüllt diesen Zweck ohne proprietäres Dokumentationsformat und ohne zusätzliche Cloud-Plattform.
Die SQLite-Datei bleibt unverändert. Die Dokumentation bleibt exportierbar. Gespeicherte Abfragen können reale Datenzustände sichtbar machen.
Gerade bei lokalen Datenbanken ist das für mich der entscheidende Punkt: Die Dokumentation liegt nicht in einem getrennten System, sondern bleibt der Datenbank zugeordnet, für die sie geschrieben wurde.
FAQ
Wie erstelle ich ein Data Dictionary für eine SQLite-Datenbank?
Ein SQLite Data Dictionary kann als Markdown-Dokument aufgebaut werden. Darin werden Tabellen, Spalten, Datentypen, erlaubte Werte, Beziehungen, Datenquellen und fachliche Regeln beschrieben. SQLite Hub ordnet solche Dokumente direkt einer lokalen Datenbank zu.
Was sollte ein SQLite Data Dictionary enthalten?
Sinnvoll sind Tabellenbeschreibungen, Spaltendefinitionen, Datentypen, erlaubte Werte, Beispiele, Beziehungen, Datenquellen, Zeitformate, bekannte Einschränkungen und Hinweise zur Datenqualität.
Speichert SQLite Hub die Markdown-Dokumentation in der SQLite-Datei?
Nein. SQLite Hub verwaltet die Markdown-Dokumente getrennt von der eigentlichen SQLite-Datei und ordnet sie der jeweiligen Datenbank zu. Die Datenbank bleibt eine normale und portable SQLite-Datei.